MemoryManager 内存管理
spark 是一个基于内存的分布式计算引擎,虽然 spark 也支持磁盘存储,但其主要的优势在于充分利用内存计算,因此理解它的内存管理原理非常重要。 另外由于它本身也对内存的使用和管理进行了一系列的优化,因此理解这些优化点,对于深入理解 spark 的内存管理模型、甚至自己开发程序都很有帮助。
内存的使用和管理,个人认为可以分成两个不同的问题:
- 内存的管理,在于其内存模型,如何充分利用内存完成计算任务。
- 内存的使用,则主要在于如何申请内存并优化读写,尤其是 rdd 缓存时申请内存和 task 计算时申请内存两种方式的不同。
当然,由于内存使用和管理是紧密联系的,个人只是为了写博客时能从一个尽量小的关注点切入才这样处理。因此,本文只分析内存的管理模型, 内存申请和使用的流程,在后面的博客中再进行分析。
由于 spark 内存管理模型,网上分析的文章已经很多,这里会引用一些网上的文章。如引用 1 讲的就比较明确,但未结合源码,讲的层次比较高,对于入门者来说略有难度。这里我尽量学习对方的优点, 并尝试结合源码来分析。
spark 内存按作用分类,主要分为存储内存(Storage Memory)、执行内存(Execution Memory)和其它内存(Other Memory).
- 存储内存:主要用来缓存 rdd 数据、广播变量数据等;
- 执行内存:主要是任务执行 shuffle 时占用的内存
- 其它内存:除上述两种数据外的其它数据,一般都在其它内存部分,如 spark 内存的实例对象,用户定义的 spark 应用中的对象等。
spark 内存的存储级别有 7 个,这是由类 StorageLevel 决定的: StorageLevel 可以决定数据使用磁盘、堆内内存、堆外内存进行存储,还可以决定数据是否序列化以及是否备份。
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
数据的序列化带来的好处是:
- 数据序列化后会连续存储,能充分利用内存空间,数据访问也更快。
- 数据序列化后可以精确计算数据序列化后的大小,对内存的使用更加精确。
但数据序列化会带来 cpu 消耗,使用数据时还需要逆序列化为 java 对象,因此需要根据自己的需要决定。
从而,spark 数据存储的级别有:
/** 不存储 */
val NONE = new StorageLevel(false, false, false, false)
/** 只使用磁盘存储,只有一个副本,即无备份 */
val DISK_ONLY = new StorageLevel(true, false, false, false)
/** 只使用磁盘存储,但有2个副本,即有一个远程备份 */
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
/** 只使用堆内内存存储,但存储前要进行序列化,只有一个副本,即无备份 */
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
/** 只使用堆内内存存储,但存储前要进行序列化,但有2个副本,即有一个远程备份 */
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
/** 同时使用堆内内存和磁盘进行存储,即当堆内内存不足时,可以写入磁盘 */
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
/** 可以使用磁盘、堆内内存、堆外内存进行存储,只有一个副本 */
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
堆内外内存
很明确,我们提到的 spark 内存,指的是 executor 端内存管理,而非 driver 端的内存。executor 端的内存,包括堆内内存与堆外内存两部分。
spark 对堆内内存的使用有着明确的规划和分配,以便充分利用内存。同时,spark 也引入了堆外内存,从而可以直接在 worker 节点的系统内存中开辟内存使用,进一步优化了内存的使用。
堆内内存
spark 堆内内存是在启动时,通过参数 spark.executor.memory 指定的。 由于 spark 对堆内内存的管理是一种逻辑上的“规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,spark 只能在申请后和释放前记录这些内存, 如图所示:
堆外内存
为了进一步优化内存,以及提高 shuffle 时排序的效率,spark 引入堆外内存,从而可以直接在 worker 节点的系统内存申请内存,存储经过序列化的二进制数据。 spark 利用 JDK Unsafe API( 从 Spark 2.0 开始,管理堆外存储内存时不再基于 Tachyon, 而是与堆外的执行内存一样,基于 JDK Unsafe API 实现).
spark 使用堆外内存可以直接操作系统内存,减少内存拷贝与 GC 扫描与回收,提高了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相对堆内内存来说, 降低了管理难度和误差。
堆外内存默认不开启,可以通过配置 spark.memory.offHeap.enabled 参数启用,并通过配置 spark.memory.offHeap.size 设定堆外内存的大小。除了 other 空间,堆内内存与堆外内存的划分方式相同。
MemoryManager 内存管理涉及主要的类
- MemoryManager: 抽象的内存管理器,能加强存储内存和执行内存之间的内存共享。
- StaticMemoryManager: 静态内存管理器,把堆内存分区为不相交的部分,即存储内存和执行内存无法共享,是 spark 1.5 及以前的版本中的内存管理器。
- UnifiedMemoryManager: 统一内存管理器,通过一个在存储内存和执行内存之间的软边界,使双方在自身内存不足时,可以临时从对方借用内存。
- StorageMemoryPool: 存储内存池,通过订阅机制来管理可调整大小的内存,即可以管理堆上存储内存,也可以管理堆上的执行内存,甚至可以管理堆外内存。 需要注意的是,由于是订阅机制,即使 spark 已经 release 了内存,但 jvm 可能并没有将内存释放掉,所以仍然可能造成 OOM.
- MemoryStore: 在内存中存储 blocks, 以 序列化的 java objects 的数组的形式,或序列化的 ByteBuffer
MemoryManager 内存大小初始化
从 MemoryManager 的构造函数可以看出,在初始化 MemoryManager 时就明确了堆上的存储内存 onHeapStorageMemory 和堆上的执行内存 onHeapExecutionMemory 的大小,
而堆外内存则是实例化 MemoryManager 时,从配置读取字段 spark.memory.offHeap.size 获取到的。
/** 初始化 MemoryManager 时,给定了堆上存储内存和堆上执行内存的大小 */
private[spark] abstract class MemoryManager(
conf: SparkConf,
numCores: Int,
onHeapStorageMemory: Long,
onHeapExecutionMemory: Long) extends Logging {
/** -- Methods related to memory allocation policies and bookkeeping ------------------------------ */
/** 堆上/堆外 存储内存,以及堆上/堆外 执行内存,都是 StorageMemoryPool, 即其管理都是 bookkeep 机制 */
@GuardedBy("this")
protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP)
@GuardedBy("this")
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP)
/** 初始化堆上存储内存/执行内存的最大值 */
onHeapStorageMemoryPool.incrementPoolSize(onHeapStorageMemory)
onHeapExecutionMemoryPool.incrementPoolSize(onHeapExecutionMemory)
/** 从配置文件获取堆外内存的最大值,并进一步确认堆外存储内存和堆外执行内存的比例 */
protected[this] val maxOffHeapMemory = conf.getSizeAsBytes("spark.memory.offHeap.size", 0)
protected[this] val offHeapStorageMemory =
(maxOffHeapMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong
/** 初始化堆外存储内存/执行内存的最大值 */
offHeapExecutionMemoryPool.incrementPoolSize(maxOffHeapMemory - offHeapStorageMemory)
offHeapStorageMemoryPool.incrementPoolSize(offHeapStorageMemory)
/** skip other codes here */
}
MemoryManager 内存管理接口
MemoryManager 为管理存储内存和执行内存提供了统一的接口, 只需要指定 MemoryMode,即使用堆内内存还是堆外内存,即可完成 内存的管理操作。
/** 获取存储内存 */
def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
/** 获取执行内存 */
def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long
/** 获取展开内存, 展开内存是执行 shuffle 过程中,展开 rdd 的 iterator 等消耗的内存, 展开内存使用的也是存储内存 */
def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
/** 释放存储内存 */
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit
/** 释放执行内存 */
def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit
/** 释放展开内存 */
def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unit
内存空间分配
前面提到,spark 的 MemoryManager 是一个抽象类,它的真正实现是 StaticMemoryManager 和 UnifiedMemoryManager, 通过配置
spark.memory.useLegacyMode 决定是否使用遗留的模式,默认为 false,即使用 UnifiedMemoryManager.
StaticMemoryManager 静态内存管理
静态内存管理,是指存储内存、执行内存和其它内存的大小在 spark 应用程序运行期间固定不变,但用户可以在程序启动之前配置,
堆内内存的分配, 如图所示:
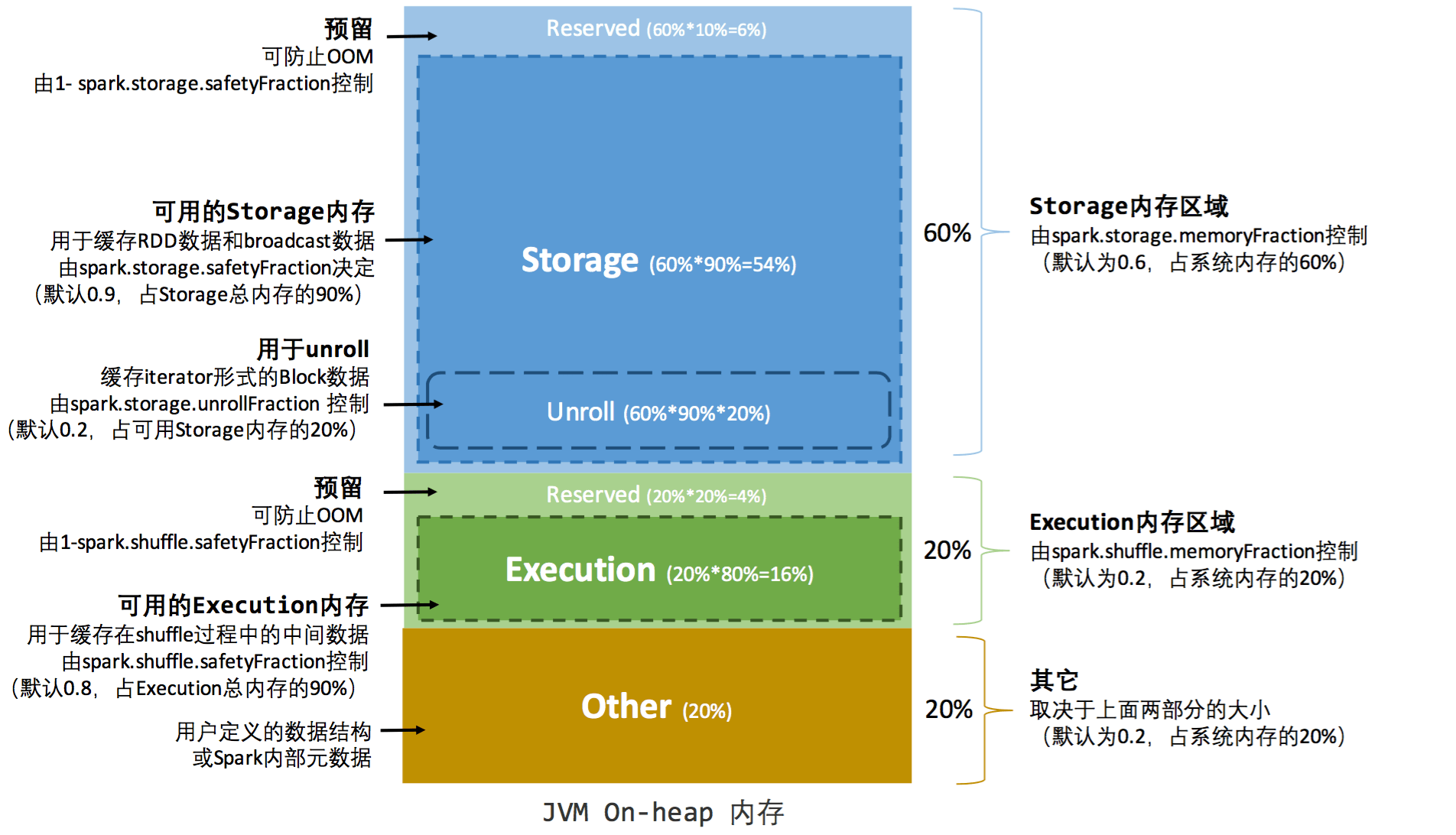
堆内内存的计算方式为:
- 存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
- 执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
上面公式中的 safetyFraction 是为了留出一块保险区域,降低 OOM 风险。但这块区域仅仅中逻辑上的规划,在具体使用上,spark 把这部分超出 safetyFraction 的内存和其它内存一样对待。
堆外内存的分配比较简单,只有存储内存和执行内存,如图所示:
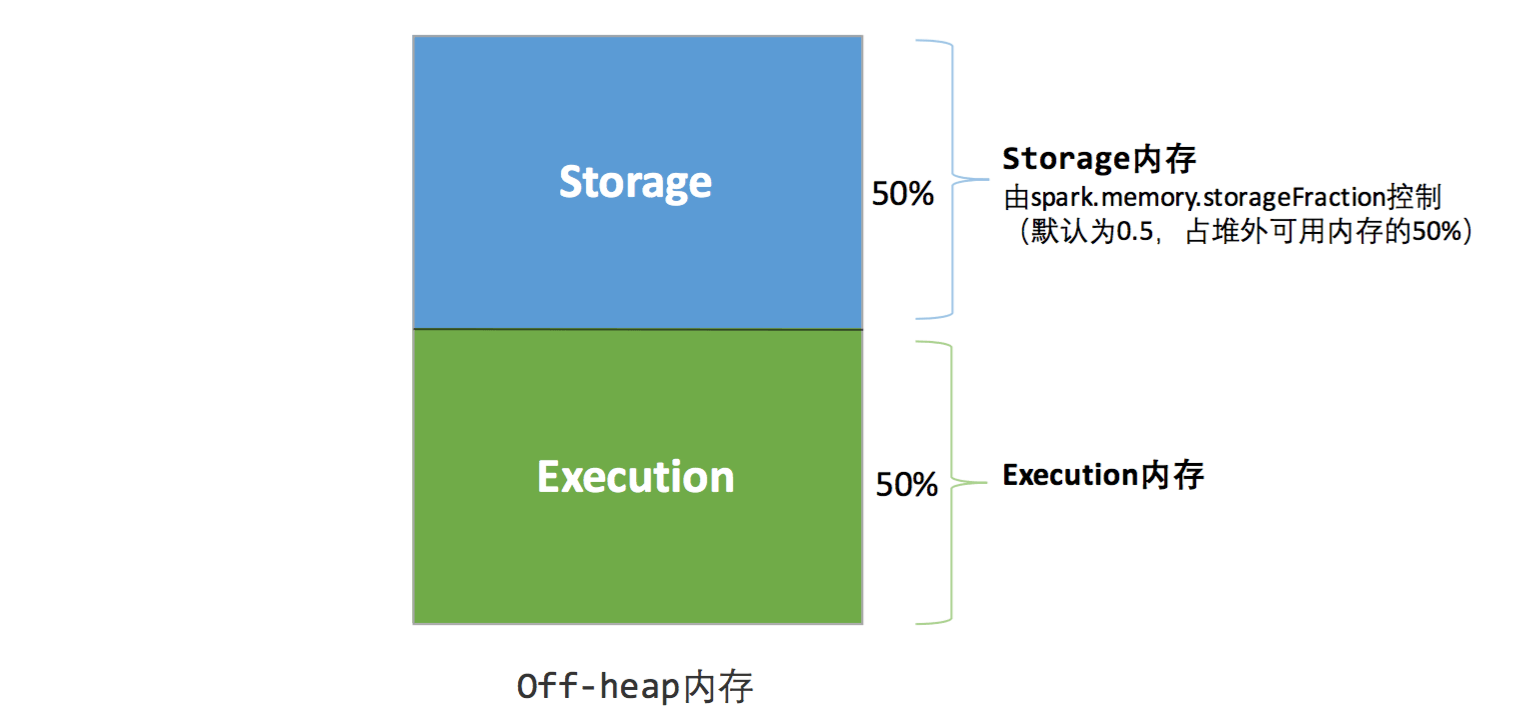
静态内存管理由于管理较为简单,无法根据数据规模和计算任务做相应的配置,很容易造成存储内存和执行内存一个使用完了,另一个却还有大量剩余的情况。这就需要新的内存管理机制的出现,即 (统一内存管理模型)[https://issues.apache.org/jira/secure/attachment/12765646/unified-memory-management-spark-10000.pdf]。但老的静态内存管理机制仍然得以保留,以兼容旧版本的应用程序。
StaticMemoryManager 的 acquireStorageMemory 方法
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
/** 静态内存管理机制不支持堆外存储内存 */
require(memoryMode != MemoryMode.OFF_HEAP,
"StaticMemoryManager does not support off-heap storage memory")
/** 如果要申请的内存大于最大堆内存储内存的大小,则表示此次获取内存失败 */
if (numBytes > maxOnHeapStorageMemory) {
/** Fail fast if the block simply won't fit */
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxOnHeapStorageMemory bytes)")
false
} else {
/** 通过内存池获取内存 */
onHeapStorageMemoryPool.acquireMemory(blockId, numBytes)
}
}
StorageMemoryPool 的 acquireMemory 方法
从 StaticMemoryManager 的 acquireStorageMemory 的方法中,我们知道,获取内存,都是先通过内存池 StorageMemoryPool 来 bookkeep 相应的内存,然后才能使用。事实上,不论是堆内还是堆外, 不论是存储内存还是执行内存或其它内存,不论是当前的静态内存管理机制还是后面的统一内存管理机制,使用内存前,都需要先通过 StorageMemoryPool 的 acquireMemory 方法来声明内存使用量。
/** Acquire N bytes of memory to cache the given block, evicting existing ones if necessary. */
/** @return whether all N bytes were successfully granted. */
def acquireMemory(blockId: BlockId, numBytes: Long): Boolean = lock.synchronized {
/** 申请内存时,先取 0 与 申请的内存减去可用内存后的差 之间的最大值; 即申请的内存时,若申请的内存超过可用内存,则考虑释放一部分内存 */
val numBytesToFree = math.max(0, numBytes - memoryFree)
acquireMemory(blockId, numBytes, numBytesToFree)
}
/** Acquire N bytes of storage memory for the given block, evicting existing ones if necessary. */
/** @param blockId the ID of the block we are acquiring storage memory for */
/** @param numBytesToAcquire the size of this block */
/** @param numBytesToFree the amount of space to be freed through evicting blocks */
/** @return whether all N bytes were successfully granted. */
def acquireMemory(
blockId: BlockId,
numBytesToAcquire: Long,
numBytesToFree: Long): Boolean = lock.synchronized {
assert(numBytesToAcquire >= 0)
assert(numBytesToFree >= 0)
assert(memoryUsed <= poolSize)
/** 若可用内存小于申请的内存,则先释放一部分内存 */
/** 这个方法放在内存申请和释放的流程里,不在内存分配的分析博客部分 */
if (numBytesToFree > 0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode)
}
/** NOTE: If the memory store evicts blocks, then those evictions will synchronously call */
/** back into this StorageMemoryPool in order to free memory. Therefore, these variables */
/** should have been updated. */
/** 如果 memory store 已经释放了 blocks,这个释放会同步调用当前的 StorageMemoryPool 来释放内在。*/
/** 因此,上面释放完成后,这里的 memoryFree 等值应该已经更新过了 */
/** 若此时需要申请的内存小于了可用的内存,则标记使用过的内存为原来的值加上本次要申请的值 */
val enoughMemory = numBytesToAcquire <= memoryFree
if (enoughMemory) {
_memoryUsed += numBytesToAcquire
}
enoughMemory
}
StaticMemoryManager 的 acquireUnrollMemory 方法
override def acquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
/** 由于 unroll 内存使用的同样是 storage memory,所以同样不支持堆外内存 */
require(memoryMode != MemoryMode.OFF_HEAP,
"StaticMemoryManager does not support off-heap unroll memory")
/** 获取内存时,都需要考虑需要申请的内存是否超过了现有的可用内存,以致是否需要释放一部分内存 */
/** 对于 Unroll 内存而言,需要知道最大的 unroll 内存值,当前使用了的 unroll 内存值,以及存储内存的可用内存值, 以确定需要释放的内存值 */
val currentUnrollMemory = onHeapStorageMemoryPool.memoryStore.currentUnrollMemory
val freeMemory = onHeapStorageMemoryPool.memoryFree
/** When unrolling, we will use all of the existing free memory, and, if necessary, */
/** some extra space freed from evicting cached blocks. We must place a cap on the */
/** amount of memory to be evicted by unrolling, however, otherwise unrolling one */
/** big block can blow away the entire cache. */
val maxNumBytesToFree = math.max(0, maxUnrollMemory - currentUnrollMemory - freeMemory)
/** Keep it within the range 0 <= X <= maxNumBytesToFree */
val numBytesToFree = math.max(0, math.min(maxNumBytesToFree, numBytes - freeMemory))
/** unroll memory 也是从堆上的存储内存池中申请内存的 */
onHeapStorageMemoryPool.acquireMemory(blockId, numBytes, numBytesToFree)
}
StaticMemoryManager 的 acquireExecutionMemory 方法
静态内存管理中,执行内存可以使用堆外内存,并从相应的内存池中获取内存
private[memory]
override def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.acquireMemory(numBytes, taskAttemptId)
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.acquireMemory(numBytes, taskAttemptId)
}
}
ExecutionMemoryPool 的 acquireMemory 方法
/** Try to acquire up to `numBytes` of memory for the given task and return the number of bytes */
/** obtained, or 0 if none can be allocated. */
/** 尝试为给定的 task 获取 numBytes 大小的内存,并返回直正获取到的 bytes 值。如果没获取到内存,则为 0 */
/** This call may block until there is enough free memory in some situations, to make sure each */
/** task has a chance to ramp up to at least 1 / 2N of the total memory pool (where N is the # of */
/** active tasks) before it is forced to spill. This can happen if the number of tasks increase */
/** but an older task had a lot of memory already. */
/** 在某些情况下,这个方法可能阻塞,直到执行内存中有了足够的内存,以保证在 task 被强制 spill 之前,*/
/** 每个 task 能获得最少内存池的 1 / 2N 的内存,其中 N 是 active tasks 的数量. 这种情况在 task 数目增加, */
/** 但老的 task 已经占用了大量内存的情况下发生 */
/** @param numBytes number of bytes to acquire */
/** @param taskAttemptId the task attempt acquiring memory */
/** @param maybeGrowPool a callback that potentially grows the size of this pool. It takes in */
/** one parameter (Long) that represents the desired amount of memory by */
/** which this pool should be expanded. */
/** 一个回调函数,可以增加 pool 的 size。 它有一个参数,表示这个 pool 应该增加的内存的量 */
/** @param computeMaxPoolSize a callback that returns the maximum allowable size of this pool */
/** at this given moment. This is not a field because the max pool */
/** size is variable in certain cases. For instance, in unified */
/** memory management, the execution pool can be expanded by evicting */
/** cached blocks, thereby shrinking the storage pool. */
/** 一个回调函数,返回当前最大的可接受的 pool 的大小。这不是一个字段,因为 max pool size 在某些情况下 */
/** 是个变量。例如,在统一内存管理机制中,执行内在能够以释放缓存 blocks 的方式增加,从而收集存储内存池 */
/** @return the number of bytes granted to the task. */
private[memory] def acquireMemory(
numBytes: Long,
taskAttemptId: Long,
maybeGrowPool: Long => Unit = (additionalSpaceNeeded: Long) => Unit,
computeMaxPoolSize: () => Long = () => poolSize): Long = lock.synchronized {
assert(numBytes > 0, s"invalid number of bytes requested: $numBytes")
/** TODO: clean up this clunky method signature */
/** Add this task to the taskMemory map just so we can keep an accurate count of the number */
/** of active tasks, to let other tasks ramp down their memory in calls to `acquireMemory` */
/** 把当前的 taskAttemptId 添加到 memoryForTask 这个 map 映射中,以保证我们能获取准确的当前 */
/** active task 的数目,让其它 tasks 减少自己的内存占用 */
if (!memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) = 0L
/** This will later cause waiting tasks to wake up and check numTasks again */
lock.notifyAll()
}
/** Keep looping until we're either sure that we don't want to grant this request (because this */
/** task would have more than 1 / numActiveTasks of the memory) or we have enough free */
/** memory to give it (we always let each task get at least 1 / (2 * numActiveTasks)). */
/** TODO: simplify this to limit each task to its own slot */
/** 无限循环,直到我们能保证至少给当前的 task 最少 1 / (2 * numActiveTasks) 的内存 */
while (true) {
/** 当前的 active task 的数目 */
val numActiveTasks = memoryForTask.keys.size
/** 当前 task 当前获取到的内存 */
val curMem = memoryForTask(taskAttemptId)
/** In every iteration of this loop, we should first try to reclaim any borrowed execution */
/** space from storage. This is necessary because of the potential race condition where new */
/** storage blocks may steal the free execution memory that this task was waiting for. */
/** 在每次循环中,我们应该首先尝试释放任何被 storage 借用的执行内存。这是必须的,由于潜在的 */
/** 条件竞争——新的存储 block 可能偷用当前的 task 等待使用的空闲执行内存 */
/** 由于内存管理,执行内存与存储内存采用了估算的形式,而且 spark 使用 bookkeep 的形式,所以 */
/** 真正的内存管理存在少量的误差,造成这种内存存在借用的情况, 所以这个方法就是获取当前仍然可能 */
/** 可以使用的执行内存 */
maybeGrowPool(numBytes - memoryFree)
/** Maximum size the pool would have after potentially growing the pool. */
/** 前面翻译掉存储内存可能占用的内存后,当前可用执行内存的最大值 */
/** This is used to compute the upper bound of how much memory each task can occupy. This */
/** must take into account potential free memory as well as the amount this pool currently */
/** occupies. Otherwise, we may run into SPARK-12155 where, in unified memory management, */
/** we did not take into account space that could have been freed by evicting cached blocks. */
/** 这里用来计算每个 task 可以获取内存的上限(最多为内存池的 1 / numActiveTasks)。这部分内存必须 */
/** 考虑,否则我们可能会碰到 SPARK-12155, 在统一内存管理机制中, 我们不考虑那些可能已经通过释放 */
/** 缓存的 blocks 释放的内存空间 */
val maxPoolSize = computeMaxPoolSize()
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
/** How much we can grant this task; keep its share within 0 <= X <= 1 / numActiveTasks */
/** maxToGrant 表示我们能授予这个 task 的内存 */
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
/** Only give it as much memory as is free, which might be none if it reached 1 / numTasks */
val toGrant = math.min(maxToGrant, memoryFree)
/** We want to let each task get at least 1 / (2 * numActiveTasks) before blocking; */
/** if we can't give it this much now, wait for other tasks to free up memory */
/** (this happens if older tasks allocated lots of memory before N grew) */
/** 我们希望在阻塞之前,让每个 task 获得至少 1 / (2 * numActiveTasks) 的内存。如果我们现在不能做到,*/
/** 则等待其它 task 来释放内在 */
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
}
0L /** Never reached */
}
MemoryManager 的 releaseStorageMemory 方法
注意:MemoryManager 的 releaseUnrollMemory 的方法调用的是 releaseStorageMemory 方法,因此这里的分析跳过
/** Release N bytes of storage memory. */
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapStorageMemoryPool.releaseMemory(numBytes)
case MemoryMode.OFF_HEAP => offHeapStorageMemoryPool.releaseMemory(numBytes)
}
}
StorageMemoryPool 的 releaseMemory 方法
从这里我们知道,释放存储内存里,spark 只是简单地做了标记,真正的 JVM 释放 spark 并未控制,也控制不了。
def releaseMemory(size: Long): Unit = lock.synchronized {
if (size > _memoryUsed) {
logWarning(s"Attempted to release $size bytes of storage " +
s"memory when we only have ${_memoryUsed} bytes")
_memoryUsed = 0
} else {
_memoryUsed -= size
}
}
MemoryManager 的 releaseExecutionMemory 方法
/** Release numBytes of execution memory belonging to the given task. */
private[memory]
def releaseExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Unit = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.releaseMemory(numBytes, taskAttemptId)
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.releaseMemory(numBytes, taskAttemptId)
}
}
ExecutionMemoryPool 的 releaseMemory 方法
对执行内存的释放,虽然略微复杂一点,因为需要针对 task 做处理,也并未真正释放内存。
/** Release `numBytes` of memory acquired by the given task. */
def releaseMemory(numBytes: Long, taskAttemptId: Long): Unit = lock.synchronized {
val curMem = memoryForTask.getOrElse(taskAttemptId, 0L)
var memoryToFree = if (curMem < numBytes) {
logWarning(
s"Internal error: release called on $numBytes bytes but task only has $curMem bytes " +
s"of memory from the $poolName pool")
curMem
} else {
numBytes
}
if (memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) -= memoryToFree
if (memoryForTask(taskAttemptId) <= 0) {
memoryForTask.remove(taskAttemptId)
}
}
lock.notifyAll() /** Notify waiters in acquireMemory() that memory has been freed */
}
UnifiedMemoryManager 统一内存管理
spark 1.6 引入了统一内存管理机制,它最大的特点是:存储内存与执行内存共享同一块内存空间,可以动态占用对方的空闲区域。
堆内内存的分配,如图所示:
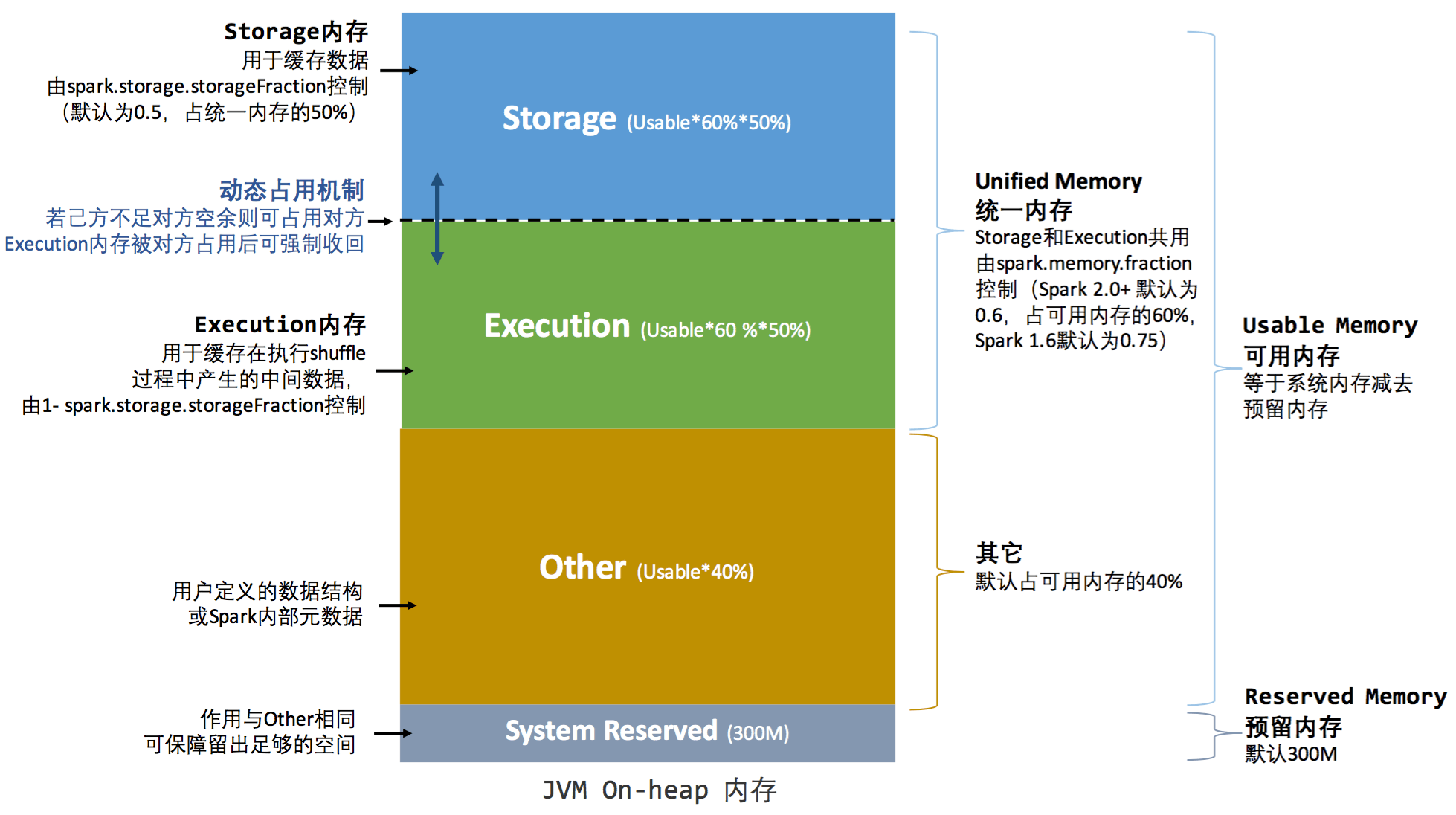
堆外内存分配与静态内存管理机制的默认分配一致,均为存储内存与执行内存默认各占 50%.
统一内存管理机制的动态占用机制为:
- 设定基本的存储内存和执行内存,该设定明确了双方各自拥有的空间范围
- 双方空间都不足时,存储到磁盘; 若已方空间不足,而对方空间剩余时,可借用对方的空间. (存储空间不足指不足以放下一个完整的 Block)
- 执行内存的空间被对方占用后,可以让对方将占用的部分转存到磁盘,然后归还借用的空间。
- 存储内存的空间被对方占用后,无法让对方归还,因为需要考虑 shuffle 过程中的很多因素,实现转为复杂。
虽然凭借统一内存管理机制,可以在一定程度上提高堆内与堆外内存资源的利用率,降低了 spark 的维护难度,但仍然一定的问题,如存储内存的空间太大或缓存的数据过多时,会导致频繁的全量的垃圾回收, 并降低任何执行的性能,因为缓存的 rdd 数据通常是长驻内存的。
UnifiedMemoryManager 的 acquireStorageMemory 方法
根据内存模式获取当前的执行内存池、存储内存池以及最大内存(堆内或堆外)
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
assertInvariants()
assert(numBytes >= 0)
val (executionPool, storagePool, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
maxOnHeapStorageMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
maxOffHeapStorageMemory)
}
if (numBytes > maxMemory) {
/** Fail fast if the block simply won't fit */
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxMemory bytes)")
return false
}
/** 当所需要的内存 numBytes 大于存储内存池的空闲内存时,需要考虑从执行内存借内存, 这里的逻辑比较简单 */
if (numBytes > storagePool.memoryFree) {
/** There is not enough free memory in the storage pool, so try to borrow free memory from */
/** the execution pool. */
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree,
numBytes - storagePool.memoryFree)
executionPool.decrementPoolSize(memoryBorrowedFromExecution)
storagePool.incrementPoolSize(memoryBorrowedFromExecution)
}
storagePool.acquireMemory(blockId, numBytes)
}
UnifiedMemoryManager 的 acquireUnrollMemory 方法
申请 unroll 内存没有什么,申请的内存是存储内存的部分
override def acquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
acquireStorageMemory(blockId, numBytes, memoryMode)
}
UnifiedMemoryManager 的 acquireExecutionMemory 方法
/** Try to acquire up to `numBytes` of execution memory for the current task and return the */
/** number of bytes obtained, or 0 if none can be allocated. */
/** 尝试为当前的 task 申请 numBytes 大小的执行内存, 返回直接申请到的内存的大小,如果没申请到则为 0 */
/** This call may block until there is enough free memory in some situations, to make sure each */
/** task has a chance to ramp up to at least 1 / 2N of the total memory pool (where N is the # of */
/** active tasks) before it is forced to spill. This can happen if the number of tasks increase */
/** but an older task had a lot of memory already. */
/** 这个方法在某些情况下会阻塞,直到申请到足够的可用内存,以保证 active task 在被 force to spill 之前, */
/** 能够获取最少总内存池的 1 / 2N 的内存。这种情况一种发生在一个老的 task 占用了大量内在,但 task 的数量 */
/** 在增加的时候 */
override private[memory] def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long = synchronized {
assertInvariants()
assert(numBytes >= 0)
/** onHeapStorageRegionSize 表示存储区域的大小,但需要注意的是, 这个区域并不是不变的,执行内存可能会 */
/** 从存储内存借用。另外,只有当真正的存储内存的使用量超过这个 region 的时候,缓存的 blocks 才会被释放 */
val (executionPool, storagePool, storageRegionSize, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
onHeapStorageRegionSize,
maxHeapMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
offHeapStorageMemory,
maxOffHeapMemory)
}
/** Grow the execution pool by evicting cached blocks, thereby shrinking the storage pool. */
/** 通过释放缓存的 blocks, 收缩存储内存池的大小,实现执行内存池的增长 */
/** When acquiring memory for a task, the execution pool may need to make multiple */
/** attempts. Each attempt must be able to evict storage in case another task jumps in */
/** and caches a large block between the attempts. This is called once per attempt. */
/** 当为一个 task 申请内存时,执行内存池可能会进行多次尝试。每次尝试都要能够释放存储,以防 */
/** 在多次尝试之间,有另一个 task 插入进来,并缓存一个大的 block。这个方法每次尝试都会调用 */
def maybeGrowExecutionPool(extraMemoryNeeded: Long): Unit = {
if (extraMemoryNeeded > 0) {
/** There is not enough free memory in the execution pool, so try to reclaim memory from */
/** storage. We can reclaim any free memory from the storage pool. If the storage pool */
/** has grown to become larger than `storageRegionSize`, we can evict blocks and reclaim */
/** the memory that storage has borrowed from execution. */
/** 如果执行内存没有足够的可用内存,则尝试从存储内存中回收内存。 */
/** 要回收的内存最大值,是存储内存可用内存的值,与存储内存占用执行内存的值之间的较大的值 */
/** 我们可以从存储内存中回收任意内存。如果存储内存池的内存大小已经大于 storageRegionSize, */
/** 我们会回收 blocks, 以及存储内存从执行内存中借用的内存. */
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
/** Only reclaim as much space as is necessary and available: */
val spaceToReclaim = storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
}
/** The size the execution pool would have after evicting storage memory. */
/** 计算收回存储内存后,执行内存的大小 */
/** The execution memory pool divides this quantity among the active tasks evenly to cap */
/** the execution memory allocation for each task. It is important to keep this greater */
/** than the execution pool size, which doesn't take into account potential memory that */
/** could be freed by evicting storage. Otherwise we may hit SPARK-12155. */
/** 执行内存池将执行内存的大小平均地分配到活动内存中,以限制每个任务的执行内存分配。*/
/** Additionally, this quantity should be kept below `maxMemory` to arbitrate fairness */
/** in execution memory allocation across tasks, Otherwise, a task may occupy more than */
/** its fair share of execution memory, mistakenly thinking that other tasks can acquire */
/** the portion of storage memory that cannot be evicted. */
def computeMaxExecutionPoolSize(): Long = {
maxMemory - math.min(storagePool.memoryUsed, storageRegionSize)
}
/** 执行内存增加的方法,和计算最大执行内存池大小的方法,都作为参数传到 acquireMemory 方法中 */
/** 回顾 ExecutionMemoryPool 的方法 acquireMemory, 这里对统一内存管理的处理就有意义了,而静态内存管理则不使用 */
/** 这两个参数就非常重要了 */
executionPool.acquireMemory(
numBytes, taskAttemptId, maybeGrowExecutionPool, computeMaxExecutionPoolSize)
}
TODO: 其实关于 spark 存储内存和执行内存的借用关系,这里有点儿抄代码的嫌疑,并没有完全分析清楚,后续再来分析。
UnifiedMemoryManager 释放内存
UnifiedMemoryManager 释放内存的逻辑,与 StaticMemoryManager 释放内存是一致的,都在 MemoryManager 中实现,底层是由 StorageMemoryPool 和 ExecutionMemoryPool 实现的。 因此这里就不再讲了。