Abstract
难点: 在 Facebook, 在社交网络中搜索不仅要关注 query text, 还要考虑 searcher 的社交上下文, 这带来了不同的挑战.
本文讨论了 embedding-based retrieval(EBR) 技术在 fb 的应用: 1) 建立了 unified embedding framework 来建模 sematic embeddings 以用于人性化搜索; 2) 在基于倒排索引的搜索引擎中使用基于 ERB 提供线上服务; 3) 一些端到端的系统优化 tricks 和经验, 包括 ANN 参数调优和全栈优化.
1.简介
搜索技术主要方法是 term matching methods (指 TF-IDF 等), 但 sematic matching 领域仍然存在挑战: 满足用户搜索目的但 not exact match of query text.
EBR 在搜索引擎中是个有挑战性的问题, 不仅仅因为要考虑海量的数据规模, 还要协调 EBR 和 term-based retrieval 之间的关系来为文档进行综合评分.
FB 中 EBR 不仅仅依赖 query text, 还要考虑当前的 user 及其上下文, 因此 FB 的问题不同与传统的, IR 社区活跃的 text embedding 问题, 而是更复杂的问题.
部署 ERB 到 FB 搜索引擎中, 解决了 modeling, serving 和 full-stack optimization 等多个挑战. modeling 中提出了 unified embedding, 这是个 2 路模型, 一路搜索请求(由 query text, 搜索者, 上下文组成), 另一路是 documents. 为了有效地训练模型, 我们开发了从 search log 中挖掘训练数据, 从搜索者/query/上下文/documents 中提取特征的方法. 为模型的快速迭代, 我们采用 recall metric 以便在离线状态对比模型.
构建 retrieval model 的独特挑战在于如何创建表征训练任务以有效, 高效地建模. 为些, 探索了2个方向:1) hard minging 以解决表征和学习 retrieval 任务的有效性; 2) ensemble embedding 以便将模型分为多个阶段, 每个阶段有不同的 recall 和 precision tradeoff.
模型开发完成后, 开发了多种方式解决模型线上提供服务的方式. 直接的方法是将现有 retrieval 的结果与 embedding KNN 合并, 但这是次优方式: 1) 在实验中发现有巨大的性能损耗; 2) 要维护2份索引有巨大的维护代价; 3) 两个 candidate sets 有相当部署的 overlap 使得整体上不是最高效的. 因此建立了混合 retrieval 框架来为 documents 共同打分. 即采用了 Faiss 框架并将其集成到倒排索引系统中建立混合 retrieval 系统. 上述方式解决了前面的问题, 并有2个优势: 1) 在解决搜索问题时能联合优化 embedding 和 term matching; 2) 支持 term constrained embedding KNN, 不仅高效还使 embedding KNN 更准确.
搜索系统如下图所示.
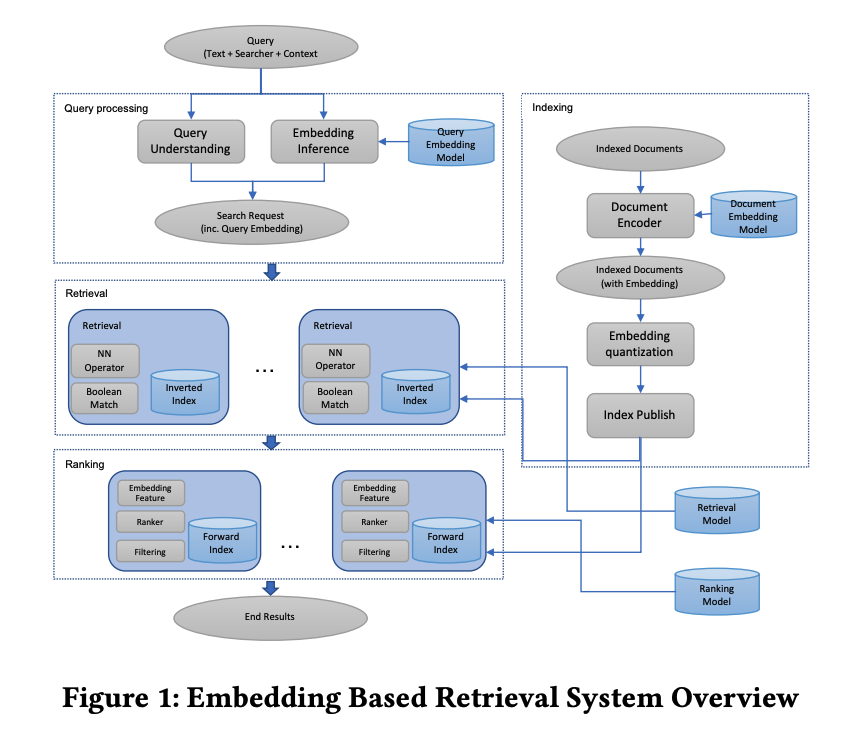
本文结构: 第2节和第3节介绍 loss function, 模型架构, 训练数据和特征工程; 第4节介绍 model serving 和系统实现; 第5节介绍后续 stage 中优化以充分发挥 embedding 优化的技术; 第6节介绍一些 advanced model techniques; 第7节 conclusion.
2.MODEL
将 retrieval task 看作 recall optimization 问题, 即给定 query, 目标结果集 $T = \lbrace t_1, t_2, \dotsb, t_N \rbrace$ 和模型 topK 结果 $\lbrace d_1, d_2, \dotsb, d_K \rbrace$, 目标是最大化 topK results:
\[\begin{gather} recall@K = \frac {\sum^K_{i=1} d_i \in T} {N} \end{gather}\]目标结果集是基于某些规则筛选出的与 query 相关的文档, 例如可以是 user click 或基于人们 rating 后的相关文档.
将 recall optimization 看作 query 与 documents 之间的距离的 ranking 问题. 其中 query 和 documents 都是 NN 给出的 dense vector, 并且采用 cosine 距离进行度量. 提出 triplet loss 来优化 NN 编码器, 又叫 embedding model.
FB 中的搜索不仅考虑 query text, 更要考虑 searcher 及其 context, 因此提出 unified embedding framework.
2.1 Evaluation Metric
虽然整体效果要使用 onlive A/B test 的结果, 但为了加快模型迭代等目的, 需要使用一个 offline metric 来评估模型, 这里采用 KNN 搜索的结果, 并以公式1中定义的 $recall@K$ 来评估模型. 具体地, 使用 1w 个query 的真值集的平均 $recall@K$ 作为评估结果.
2.2 Loss function
对于给定的 triplet $( q^i, d^i_+, d^i_- )$, 其中 $q^i$ 为 query, $d^i_+$ 和 $d^i_-$ 是相应的正负样本文档, 则 triplet loss 定义为:
\[\begin{gather} L = \sum^N_{i=1} max(0, D(q^i, d^i_+) - D(q^i, d^i_-) + m), \end{gather}\]其中 $D(u, v)$ 是向量 $u, v$ 的距离度量, m 是正负样本对的 margin, N 是训练集中 triplets 的总数. 我们发现: 精调margin m非常重要, 对不同的训练任务, 不同的 margin 值能导致 5-10% 的 KNN recall 方差.
使用随机采样生成负样本能近似召回优化任务. 如果对每个正样本, 采样 n 个负样本, 相当于在 candidate pool 是 n 时模型要优化 $recall@1$. 如果真实的 candidate pool 大小是 N, 则我们要近似优化 $K \approx N / n$ (个人理解: 相当于如果 rank 层要10选1, 则N为10, 采样2个负样本, 则K=5?). 后面会验证这个假设并提供不同的正负样本标签定义的对比.
2.3 Unified Embedding Model
模型包括3个主要组件: 1) query encoder $E(Q)=f(Q)$ 生成 query embedding; 2) document encoder $E(D)=g(D)$ 来生成 document embedding; 3) 相似度函数 $S(E(Q), E(D))$ 生成 query 与 document 之间的相似度. 两个编码器这里是2个不同的网络, 但有选项可以共享部分参数, 而相似度函数采用 cosine 相似度.
输入部分是 Unified Embedding Model 与传统的 text embedding model 最大的不同之处, 如 query 部分输入包括了用户位置, 社交关系; 而 document 部分输入包括了聚合的社交位置, FB groups 社交聚类结果等. Unified Embedding Model 构架如下图所示.
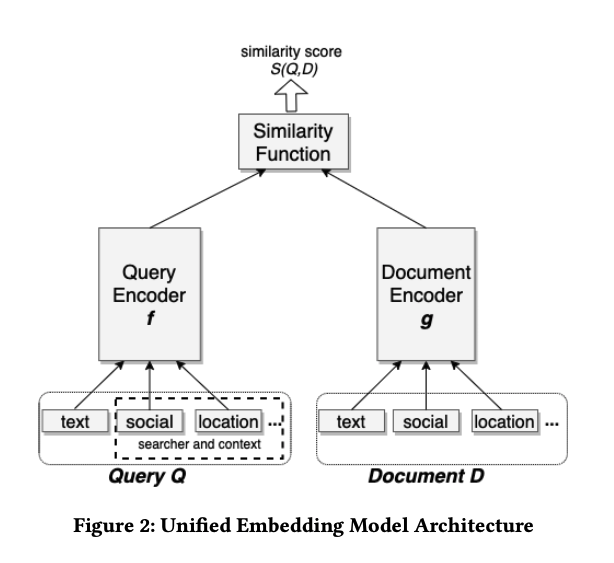
2.4 Training Data Mining
在搜索排序系统中定义正负样本标签是 non-trivial 的问题. 基于模型指标对比了一些不同的选择. 如对负样本, 在初始的实验中使用2种策略作为负样本, 而以用户点击作为正样本:
- random samples: 对每个 query, 在 document pool 中随机采样 document 作为负样本;
- non-click impressions: 对每个 query, 随机采样了曝光但用户未点击的结果作为负样本.
将曝光未点击作为负样本, 模型训练的结果明显差于随机采样负样本, 这是由于 negative bias 偏向于困难负样本, 而实际上召回时大多数都是简单负样本.
对正样本的实验也有有趣的发现:
- 点击: 以用户的点击结果作为正样本是符合设想的, 因为用户点击表明搜索结果符合预期;
- 曝光: 我们将召回视作一个快速执行的近似排序器, 因此希望召回模型的结果与排序高的结果相符, 因此曝光给用户的结果也几乎都是正样本.
实验表明, 上述两种正样本等效. 即在相同数据量下, 不同的正样本定义首先的数据集下训练的模型, 召回指标几乎相同. 另外发现, 两种定义混合的正样本不能带来收益, 且增加训练数据量也不能带来收益.
上述实验表明, 以用户点击作为正样本, 以随机采样作为负样本, 可以提供可观的收益. 进一步地, 将在第6节提供 hard mining strategy(困难样本挖掘策略)以提供模型的区分性.
3.Feature Engineering
特征工程上, Unified Embedding 比 purely text embedding 明显有更多收益(event search +18% recall improvement, group search +16% recall improvement).
Text features: character n-gram 在模型上的表现优于 word n-gram, 且对 out-of-vocabulary 的 token 更 robust; character n-gram 基础上再加上 word n-gram 能额外带来 +1.5% 的 recall improvement(即使使用了 word hash).
Location features 和 Social features 跳过.
4.Serving
4.1 ANN
部署了一个基于 ANN 的倒排索引, 因为它有更小的存储消耗, 且更容易集成到现有 retrieval 系统中. 首先采用 Faiss 对 embedding 进行量化, 然后在倒排表中进行高效地 NN 搜索。
Embedding quantization有2个主要的组件:1)coarse quantization,即将 embedding 进行粗聚类(基于K-means);2)product quantization,进行细粒度量化以便高效计算距离.(暂时用不到, 跳过)
4.2 系统实现
这里作者使用了 FB 自研组件 Unicorn(不开源),值得注意的是使用 embedding query 时,使用 vector 和 radius 进行过滤的思想,vector 为 query embedding,radius 是距离要 ≤ radius, 这是提供了较好地性能和召回结果的 tradeoff。
本节关于 hybird retrieval 和 model serving 跳过
4.3 Query And Index Selection
更多是过滤策略,提高 query 理解或减小查询规模。
5.Later-Stage Optimization
由于 EBR 提供了新的 retrieval 集合,原来的 ranking layer 需要配套改进:
- Embedding 作为 ranking 特征:实验了 cosine 相似度, Hadamard 积,raw embedding 等, cosine 相似度效果最好。(注意:这里不同场景效果如何要实验决定,FB cosine 相似度效果好,未必其它场景也是。)
- 训练数据反馈循环:尽管 EBR 能提升 recall 指标,但它在 term matching 上可能精确率更差。为此,建立了一个基于人工排序的 feedback loop, 将 EBR 的结果发送到人工进行标定与 query 是否相关,并将标定结果用于训练,以进一步提升 retrieval 准确率。
6.Advanced Topics
6.1 Hard Mining
retrieval 的数据空间对文本、语义、社交等数据有差异化的数据分布,因此设计 retrieval 模型的训练集来快速、高效地在这样的空间中学习非常重要。
6.1.1 Hard Negative Mining
困难负样本挖掘的必要性:在进行 people search 时,模型总是把相同 name 的 retrieval 排在前面,而不把真实目标(不同名字)排得更高,即使在给了社交特征的情况下也是如此,这表明模型没有充分利用社交特征。很可能的原因是,初始实验时,负样本主要随机采样产生的简单负样本(通常有不同的 name)。为了让模型更好在区分相似的结果,我们会采样一些更接近 positive 的 samples 来帮助模型区分它们。
Online Hard Negative Mining:
由于模型训练是 mini-batch updates, 因此 hard negative 的选择可以在 batch 内完成。如某个 batch 由 n 个正样本对 ${\lbrace (q^i, d^i_+) \rbrace}^n_{i=1}$. 那么对每个 query $q^i$, 我们使用其它正样本构建 candidate documents pool: ${\lbrace d_+^1, \dotsb, d^j_{+}, \dotsb, d^n_{+} | j \ne i \rbrace}$, 并从中选择 similarity score 最高的作为困难负样本构建 train triplets。Online hard negative 始终如一地提高各个领域(如text, context, social 等)的 embedding 质量,并带来 5-8% 的 recall improvement。并且观察到,每个正样本最多使用2个困难负样本,超过2个困难负样本会降低模型质量。但是,由于负样本是随机采样的,这种方式未必能产生 hard enough negative samples, 因此需要 offline hard negative mining.
Offline Hard Negative Mining:
离线负样本挖掘有如下步骤:
- 对每个 query 生成 top K 个结果
- 基于 hard negative strategy 选择 hard negatives.
- 使用新生成的 triplets 重新训练 embedding model.
- 上述循环迭代进行.
基于 Offline 和 Online 的困难负样本的对比实现表明,采用一定比例混合困难负样本和简单负样本的的条件下,Offline 的结果更优。但是:只使用困难负样本训练的 embedding model 效果不如只使用简单负样本训练的 model。进一步的分析表明,”hard” model 更关注 non-text features, 因此在 text features 上比 “easy” model 弱。
第一个经验是 hard negative stretegy:使用 hardest samples 并不是最优的策略,通过对比不同的 rank position 后发现从 rank 101-500 采样取得了最优的模型 recall。第二个经验是 retrieval task optimization: 保留简单负样本是必要的,因为 retrieval task 中主要的数据都是简单负样本。因此探索了多种处理随机采样的简单负样本和困难负样本的方法,包括从 “easy” model 迁移学习。结果,下面两种方法取得了最佳收益:
- 混合困难/简单负样本训练:逐渐增加简单负样本比例,实验表明:easy:hard=100:1时取得最优。
- 从 hard model 迁移到 easy model: 尽管反方向迁移效果不好,但从 hard model transfer to easy model 取得了更好的 recall improvement。
最后,offline 负样本挖掘中,计算 KNN 代价非常大,因此 ANN 是个可行的选择,且生成的 hard negatives 质量足够,因此训练时实际使用的是 semi-hard negatives。
6.1.2 Hard Positive Mining
Baseline embedding model 使用的是点击或曝光的正样本,这些是现有系统已经召回的样本。为最大化 EBR 收益,一个方向是识别出未被现有系统召回但是是 positive 的样本。为实现这个目标,从用户搜索日志中挖掘失败的召回结果但是是潜在的真值的样本(如被模型误判的正确样本)。这种方式能帮助模型训练,仅需要4%的点击训练数据量却能达到相似的 recall 指标。
6.2 Embedding Ensemble
更多是特定场景的实验报告,跳过。
7.Conclusion
提出了 unified embedding model 来解决社交场景下的语义相似召回问题。下一步方向:1)加深,使用更先进的模型如 BERT 等来解决 task-specified 问题; 2)通用化,利用预训练文本表征模型开发适用不同任务的文本表征子模型,进一步地开发通用的预训练 query embedding model。
8.个人总结
本文提到了很多召回场景下适用的经验和 tricks,为下一步 GC 的召回模型提供了完整的思路:
- 标签准备,基于 GC 的场景,考虑:
- 优先准备地址文本和坐标均正确的结果作为标签;
- 其次准备文本正确的结果作为标签;
- 评价指标
- 文本的评价指标 $recall@K$
- 注意 K 与召回 n 的选择及后续排序候选池 N 的关系
- 工具准备
- ANN 库及资源
- 与现有召回系统的兼容
- 样本挖掘
- 正样本
- 普通正样本,能满足基本地注,即点击或曝光,GC 就是文本相关且距离满足要求
- 困难正样本,锦上添花,即召回、排序模型误判的正样本
- 负样本
- 简单负样本
- 困难负样本
- online 困难负样本:可以作为较强的 baseline 方法
- offline 困难负样本
- 正负样本关系
- 比例关系:作者经验是 easy:hard = 100:1, 看场景
- 结合使用方法:先 hard 训练再迁移到 easy
- 正样本
- 模型
- 召回模型要能够迭代训练
- 双塔没说的
- 简单的塔,GC 中 query 塔考虑 Sentence-BERT 等,documents 塔可以考虑增加坐标作用特征输入。
- 复杂的塔,不同地址组件均作用塔的输入,如 street, house number, poi, admin, aoi 等
- 模型与正负样本的关系,包括多阶段、迁移学习等